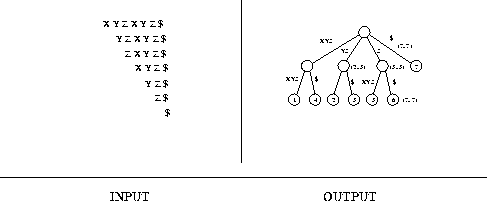
Input description: A reference string S.
Problem description: Build a data structure for quickly finding all places where an arbitrary query string q is a substring of S.
Discussion: Suffix trees and arrays are phenomenally useful data structures for solving
string problems efficiently and with elegance.
If you need to speed up a string processing algorithm from
![]() to linear time, proper use of suffix trees is quite likely the
answer.
Indeed, suffix trees are the hero of the war story reported in
Section
to linear time, proper use of suffix trees is quite likely the
answer.
Indeed, suffix trees are the hero of the war story reported in
Section ![]() .
In its simplest instantiation, a suffix tree is simply a trie
of the n strings that are suffixes of an n-character string S.
A trie is a tree structure, where each node represents one character,
and the root represents the null string.
Thus each path from the root represents a string, described by the
characters labeling the nodes traversed.
Any finite set of words defines a trie, and two words with
common prefixes will branch off from each other at the first distinguishing
character.
Each leaf represents the end of a string.
Figure
.
In its simplest instantiation, a suffix tree is simply a trie
of the n strings that are suffixes of an n-character string S.
A trie is a tree structure, where each node represents one character,
and the root represents the null string.
Thus each path from the root represents a string, described by the
characters labeling the nodes traversed.
Any finite set of words defines a trie, and two words with
common prefixes will branch off from each other at the first distinguishing
character.
Each leaf represents the end of a string.
Figure ![]() illustrates a simple trie.
illustrates a simple trie.
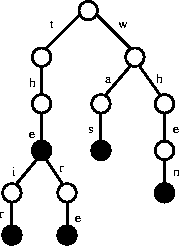
Figure: A trie on strings the, their, there, was, and when
Tries are useful for testing whether a given query string q is in the set. Starting with the first character of q, we traverse the trie along the branch defined by the next character of q. If this branch does not exist in the trie, then q cannot be one of the set of strings. Otherwise we find q in |q| character comparisons regardless of how many strings are in the trie. Tries are very simple to build (repeatedly insert new strings) and very fast to search, although they can be expensive in terms of memory.
A suffix tree is simply a trie of all the proper suffixes of S. The suffix tree enables you to quickly test whether q is a substring of S, because any substring of S is the prefix of some suffix (got it?). The search time is again linear in the length of q.
The catch is that constructing a full suffix tree in this manner
can require ![]() time and, even worse,
time and, even worse,
![]() space, since the average length of the n suffices is n/2
and there is likely to be relatively little overlap representing shared
prefixes.
However, linear space suffices to represent a full suffix tree
by being clever.
Observe that most of the nodes in a trie-based suffix tree occur
on simple paths between branch nodes in the tree.
Each of these simple paths corresponds to a substring of the original string.
By storing the original string in an array and collapsing each such path
into a single node described by the starting and ending array indices
representing the substring, we have all the information of the full suffix
tree in only O(n) space.
The output figure for this section displays a collapsed suffix tree in all
its glory.
space, since the average length of the n suffices is n/2
and there is likely to be relatively little overlap representing shared
prefixes.
However, linear space suffices to represent a full suffix tree
by being clever.
Observe that most of the nodes in a trie-based suffix tree occur
on simple paths between branch nodes in the tree.
Each of these simple paths corresponds to a substring of the original string.
By storing the original string in an array and collapsing each such path
into a single node described by the starting and ending array indices
representing the substring, we have all the information of the full suffix
tree in only O(n) space.
The output figure for this section displays a collapsed suffix tree in all
its glory.
Even better, there exist linear-time algorithms to construct this collapsed tree that make clever use of pointers to minimize construction time. The additional pointers used to facilitate construction can also be used to speed up many applications of suffix trees.
But what can you do with suffix trees? Consider the following applications. For more details see the books by Gusfield [Gus97] or Crochemore and Rytter [CR94]:
Since the linear time suffix tree construction algorithm is tricky, I recommend either starting from an existing implementation or using a simple, potentially quadratic-time incremental-insertion algorithm to build a compressed suffix tree. Another good option is to use suffix arrays, discussed below.
Suffix arrays do most
of what suffix trees do, while typically using
four times less memory than suffix trees.
They are also easier to implement.
A suffix array is basically just an array that contains all the n suffixes
of S in sorted order.
Thus a binary search of this array for string q
suffices to locate the
prefix of a suffix that matches q, permitting efficient substring
search in ![]() string comparisons.
In fact, only
string comparisons.
In fact, only ![]() character comparisons need be performed
on any query, since we can identify the next character that must be tested in
the binary search.
For example, if the lower range of the search is cowabunga
and the upper range is cowslip, all keys in between must share the same
first three letters, so only the fourth character of any intermediate key
must be tested against q.
character comparisons need be performed
on any query, since we can identify the next character that must be tested in
the binary search.
For example, if the lower range of the search is cowabunga
and the upper range is cowslip, all keys in between must share the same
first three letters, so only the fourth character of any intermediate key
must be tested against q.
The space savings of suffix arrays result because as with compressed
suffix trees, it suffices to store pointers into the original string
instead of explicitly copying the strings.
Suffix arrays use less memory than suffix trees by eliminating the need
for explicit pointers between suffixes since these are implicit in the binary
search.
In practice, suffix arrays are typically as fast or faster to search than
suffix trees.
Some care must be taken to construct suffix arrays efficiently, however, since
there are ![]() characters in the strings being sorted.
A common solution is to first build a suffix tree, then perform
an in-order traversal of it to read the strings off in sorted order!
characters in the strings being sorted.
A common solution is to first build a suffix tree, then perform
an in-order traversal of it to read the strings off in sorted order!
Implementations: Ting Chen's and Dimitris Margaritis's C language implementations
of suffix trees,
reported in the war story of Section ![]() ,
are available on the algorithm repository WWW site: http://www.cs.sunysb.edu/
,
are available on the algorithm repository WWW site: http://www.cs.sunysb.edu/ ![]() algorith.
algorith.
Bare bones implementations in C of digital and Patricia trie data structures
and suffix arrays
appear in [GBY91].
See Section ![]() for details.
for details.
Notes: Tries were first proposed by Fredkin [Fre62], the name coming from the central letters of the word ``retrieval''. A survey of basic trie data structures with extensive references appears in [GBY91]. Expositions on tries include [AHU83].
Efficient algorithms for suffix tree construction are due to Weiner [Wei73], McCreight [McC76], and Ukkonen [Ukk92]. Good expositions on these algorithms include Crochmore and Wytter [CR94] and Gusfield [Gus97]. Textbooks include [Woo93] and [AHU74], where they are called position trees. Several applications of suffix trees to efficient string algorithms are discussed in [Apo85].
Suffix arrays were invented by Manber and Myers [MM90], although an equivalent idea called Pat trees due to Gonnet and Baeza-Yates appears in [GBY91].
The power of suffix trees can be further augmented by using a data structure for computing the least common ancestor of any pair of nodes x, y in a tree in constant time, after linear-time preprocessing of the tree. The original data structure is due to Harel and Tarjan [HT84], but it was significantly simplified by Schieber and Vishkin [SV88]. Expositions include Gusfield [Gus97]. The least common ancestor (LCA) of two nodes in a suffix tree or trie defines the node representing the longest common prefix of the two associated strings. Being able to answer such queries in constant time is amazing, and useful as a building block for many other algorithms. The correctness of the LCA data structure is difficult to see; however, it is implementable and can perform well in practice.
Related Problems: string matching (see page ![]() ),
longest common substring (see page
),
longest common substring (see page ![]() ).
).