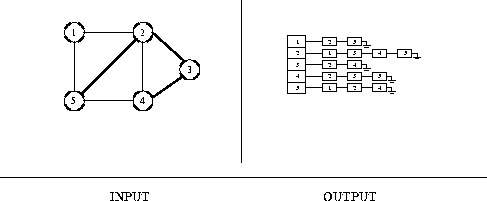
Input description: A graph G.
Problem description: Give a flexible, efficient data structure to represent G.
Discussion: While there are several possible variations,
the two basic data structures for graphs are adjacency matrices
and adjacency lists.
What these data structures actually
are is discussed in Section ![]() .
The issues in deciding which one to use include:
.
The issues in deciding which one to use include:
Building a good general-purpose graph type is surprisingly tricky and difficult. For this reason, we suggest that you check out existing implementations (particularly LEDA) before hacking up your own. Note that it costs only time linear in the size of the larger data structure to convert between adjacency matrices and adjacency lists. This conversion is unlikely to be the bottleneck in any application, if you decide you want to use both data structures and have the space to store them. This usually isn't necessary but might prove simplest if you are confused about the alternatives.
Planar graphs are those that can be drawn in the plane so that no two
edges cross.
Many graphs arising in applications are planar by definition,
such as maps of countries, while others are planar by happenstance,
like any tree.
Planar graphs are always sparse, since any n-vertex planar graph can
have at most 3n-6 edges, so they should usually be represented by
adjacency lists.
If the planar drawing (or embedding) of the graph is fundamental
to what is being computed, planar graphs are best represented
geometrically.
See Section ![]() for algorithms for constructing planar
embeddings from graphs, and Section
for algorithms for constructing planar
embeddings from graphs, and Section ![]() for algorithms maintaining graphs implicit in the arrangements of geometric
objects like lines and polygons.
for algorithms maintaining graphs implicit in the arrangements of geometric
objects like lines and polygons.
Hypergraphs are generalized graphs where each edge may link subsets of more than two vertices. For example, suppose we want to represent who is on which Congressional committee. The vertices of our hypergraph would be the individual congressmen, while each hyperedge would represent one committee. Such arbitrary collections of subsets of a set are naturally thought of as hypergraphs.
Two basic data structures for hypergraphs are:
Special efforts must be taken to represent very large graphs efficiently.
However,
interesting problems have been solved on graphs with millions of edges
and vertices.
The first step is to make your data structure as lean as possible, by
packing your adjacency matrix as a bit vector
(see Section ![]() ) or
removing extra pointers from your adjacency list representation.
For example, in a static graph (no edge insertions or deletions)
each edge list can be replaced by a packed array of vertex identifiers,
thus eliminating pointers and saving potentially half the space.
) or
removing extra pointers from your adjacency list representation.
For example, in a static graph (no edge insertions or deletions)
each edge list can be replaced by a packed array of vertex identifiers,
thus eliminating pointers and saving potentially half the space.
At some point it may become necessary to switch to a hierarchical
representation of the graph, where the vertices are clustered into subgraphs
that are compressed into single vertices.
Two approaches exist for making such a hierarchical decomposition.
The first breaks things into components in a natural or
application-specific way.
For example, knowing that your graph is a map of roads and cities suggests
a natural decomposition - partition the map into districts, towns,
counties, and states.
The other approach runs a graph partition algorithm as
in Section ![]() .
If you are performing the decomposition for space or paging reasons,
a natural
decomposition will likely
do a better job than some naive heuristic for an NP-complete problem.
Further, if your graph is really unmanageably large,
you cannot afford to do
a very good job of algorithmically partitioning it.
You should first verify that standard data structures fail on your
problem before attempting such heroic measures.
.
If you are performing the decomposition for space or paging reasons,
a natural
decomposition will likely
do a better job than some naive heuristic for an NP-complete problem.
Further, if your graph is really unmanageably large,
you cannot afford to do
a very good job of algorithmically partitioning it.
You should first verify that standard data structures fail on your
problem before attempting such heroic measures.
Implementations: LEDA (see Section ![]() )
provides the best implemented graph data type
currently available in C++.
If at all possible, you should use it.
If not, you should at least study the
methods it provides for graph manipulation, so as to see how the
right level of abstract graph type makes implementing algorithms very
clean and easy.
Although a general graph implementation like LEDA may be 2 to 5 times
slower and considerably less space efficient
than a stripped-down special-purpose implementation,
you have to be a pretty good programmer to realize this
performance improvement.
Further, this speed is likely to come at the expense of simplicity and clarity.
)
provides the best implemented graph data type
currently available in C++.
If at all possible, you should use it.
If not, you should at least study the
methods it provides for graph manipulation, so as to see how the
right level of abstract graph type makes implementing algorithms very
clean and easy.
Although a general graph implementation like LEDA may be 2 to 5 times
slower and considerably less space efficient
than a stripped-down special-purpose implementation,
you have to be a pretty good programmer to realize this
performance improvement.
Further, this speed is likely to come at the expense of simplicity and clarity.
GraphEd [Him94], written in C
by Michael Himsolt,
is a powerful
graph editor that provides an interface for application modules
and a wide variety of graph algorithms.
If your application demands interaction and visualization more than
sophisticated algorithmics, GraphEd might be the right place to start,
although it can be buggy.
GraphEd can be obtained by anonymous ftp from forwiss.uni-passau.de
(132.231.20.10) in directory /pub/local/graphed.
See Section ![]() for more details on GraphEd and
other graph drawing systems.
for more details on GraphEd and
other graph drawing systems.
The Stanford Graphbase (see Section ![]() ) provides a simple
but flexible graph data structure in CWEB, a literate version of the
C language.
It is instructive to see what Knuth does and does not place in his basic
data structure, although we recommend LEDA as a better basis for further
development.
) provides a simple
but flexible graph data structure in CWEB, a literate version of the
C language.
It is instructive to see what Knuth does and does not place in his basic
data structure, although we recommend LEDA as a better basis for further
development.
LINK is an environment for combinatorial computing that provides special support for hypergraphs, including the visualization of hypergraphs. Although written in C++, it provides a Scheme language interface for interacting with the graphs. LINK is available from http://dimacs.rutgers.edu/Projects/LINK.html .
An elementary implementation of a ``lazy'' adjacency matrix in Pascal,
which does not
have to be initialized, appears in [MS91].
See Section ![]() .
.
Simple graph data structures in Mathematica are provided
by Combinatorica [Ski90], with a library of algorithms and
display routines.
See Section ![]() .
.
Notes: It was not until the linear-time algorithms of Hopcroft and Tarjan [HT73b, Tar72] that the advantages of adjacency list data structures for graphs became apparent. The basic adjacency list and matrix data structures are presented in essentially all books on algorithms or data structures, including [CLR90, AHU83, Tar83].
An interesting question concerns minimizing the number of bits needed to represent arbitrary graphs on n vertices, particularly if certain operations must be supported efficiently. Such issues are discussed in [vL90b].
Dynamic graph algorithms are essentially data structures that maintain quick access to an invariant (such as minimum spanning tree or connectivity) under edge insertion and deletion. Sparsification [EGIN92] is a general and interesting approach to constructing dynamic graph algorithms. See [ACI92] for an experimental study on the practicality of dynamic graph algorithms.
Hierarchically-defined graphs often arise in VLSI design problems, because designers make extensive use of cell libraries [Len90]. Algorithms specifically for hierarchically-defined graphs include planarity testing [Len89], connectivity [LW88], and minimum spanning trees [Len87].
The theory of hypergraphs is presented by Berge [Ber89].
Related Problems: Set data structures (see page ![]() ),
graph partition (see page
),
graph partition (see page ![]() ).
).