``But our heuristic works very, very well in practice.'' He was simultaneously boasting and crying for help.
Unification is the basic computational mechanism in logic programming languages like Prolog. A Prolog program consists of a set of rules, where each rule has a head and an associated action whenever the rule head matches or unifies with the current computation.
An execution of a Prolog program starts by specifying a goal, say p(a,X,Y), where a is a constant and X and Y are variables. The system then systematically matches the head of the goal with the head of each of the rules that can be unified with the goal. Unification means binding the variables with the constants, if it is possible to match them. For the nonsense program below, p(X,Y,a) unifies with either of the first two rules, since X and Y can be bound to match the extra characters. The goal p(X,X,a) would only match the first rule, since the variable bound to the first and second positions must be the same.
p(a,a,a) := h(a);
p(b,a,a) := h(a) * h(b);
p(c,b,b) := h(b) + h(c);
p(d,b,b) := h(d) + h(b);
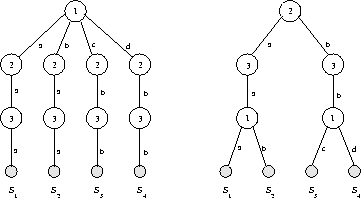
Figure: Two different tries for the given set of rule heads
``In order to speed up unification, we want to preprocess the set of rule heads so that we can quickly determine which rules match a given goal. We must organize the rules in a trie data structure for fast unification.''
Tries are extremely useful data structures in working with strings,
as discussed in Section ![]() .
Every leaf of the trie represents one string.
Each node on the path from root to leaf is labeled with exactly one
character of the string, with the ith node of the path corresponding to the
ith character of the string.
.
Every leaf of the trie represents one string.
Each node on the path from root to leaf is labeled with exactly one
character of the string, with the ith node of the path corresponding to the
ith character of the string.
``I agree. A trie is a natural way to represent your rule heads. Building a trie on a set of strings of characters is straightforward - just insert the strings one after another starting from the root. So what is your problem?'' I asked.
``The efficiency of our unification algorithm depends very much on minimizing the number of edges in the trie. Since we know all the rules in advance, we have the freedom to reorder the character positions in the rules. Instead of the root node always representing the first argument in the rule, we can choose to have it represent the third argument. We would like to use this freedom to build a minimum-size trie for the set of rules.''
He showed me the example in Figure ![]() .
A trie constructed according to the original string position order
(1, 2, 3) uses a total of 12 edges.
However, by permuting the character order to (2, 3, 1), we can obtain a trie
with only 8 edges.
.
A trie constructed according to the original string position order
(1, 2, 3) uses a total of 12 edges.
However, by permuting the character order to (2, 3, 1), we can obtain a trie
with only 8 edges.
``Why does the speed of unification depend on minimizing the number of edges in the trie?''
``An open goal is one with all distinct variables in its arguments, like p(X,Y,Z). Open goals match everything. In unifying an open goal against a set of clause heads, each symbol in all the clause heads will be bound to some variable. By doing a depth-first traversal of this minimum-edge trie, we minimize the number of operations in unifying the goal with all of the clause heads,'' he explained quickly.
``Interesting...'' I started to reply before he cut me off again.
``One other constraint. For most applications we must keep the leaves of the trie ordered, so that the leaves of the underlying tree go left-to-right in the same order as the rules appear on the page.''
``But why do you have to keep the leaves of the trie in the given order?'' I asked.
``The order of rules in Prolog programs is very, very important. If you change the order of the rules, the program returns different results.''
Then came my mission.
``We have a greedy heuristic for building good but not optimal tries, based on picking as the root the character position that minimizes the degree of the root. In other words, it picks the character position that has the smallest number of distinct characters in it. This heuristic works very, very well in practice. But we need you to prove that finding the best trie is NP-complete so our paper is, well, complete.''
I agreed to think about proving the hardness of the problem and chased
him from my office.
The problem did seem to involve some non-trivial combinatorial optimization to
build the minimal tree, but I couldn't see how to factor the left-to-right
order of the rules into a hardness proof.
In fact, I couldn't think of any NP-complete problem that had such
a left-right ordering constraint.
After all, if a given set of rules contained a character position in common
to all the rules, that character position must be probed first in any
minimum-size tree.
Since the rules were ordered, each node in the subtree must represent
the root of a run of consecutive rules, so there were only ![]() possible nodes to choose from for this tree....
possible nodes to choose from for this tree....
Bingo! That settled it.
The next day I went back to the professor and told him. ``Look, I cannot prove that your problem is NP-complete. But how would you feel about an efficient dynamic programming algorithm to find the best trie!'' It was a pleasure watching his frown change to a smile as the realization took hold. An efficient algorithm to compute what he needed was infinitely better than a proof saying you couldn't do it!
My recurrence looked something like this.
Suppose that we are given n ordered rule heads ![]() ,
each with m arguments.
Probing at the pth position,
,
each with m arguments.
Probing at the pth position, ![]() ,
partitioned the rule
heads into runs
,
partitioned the rule
heads into runs ![]() , where each rule in a given run
, where each rule in a given run
![]() had the same character value of
had the same character value of ![]() .
The rules in each run must be consecutive, so there
are only
.
The rules in each run must be consecutive, so there
are only ![]() possible runs to worry about.
The cost of probing at position p is the cost of finishing the trees formed
by each of the created runs, plus one edge per tree to link it to probe p:
possible runs to worry about.
The cost of probing at position p is the cost of finishing the trees formed
by each of the created runs, plus one edge per tree to link it to probe p:
![]()
A graduate student immediately set to work implementing dynamic programming to compare with their heuristic. On many programs the optimal and greedy algorithms constructed the exact same trie. However, for some examples, dynamic programming gave a 20% performance improvement over greedy, i.e. 20% better than very, very well in practice. The run time spent in doing the dynamic programming was sometimes a bit larger than with greedy, but in compiler optimization you are always happy to trade off a little extra compilation time for better execution time performance of your program. Is a 20% improvement worth it? That depends upon the situation. For example, how useful would you find a 20% increase in your salary?
The fact that the rules had to remain ordered was the crucial property
that we exploited in the dynamic programming solution.
Indeed, without it, I was able to prove that the problem was NP-complete,
something we put in the paper [DRR ![]() 95] to make it complete.
95] to make it complete.