Ynjiun waved his laser wand over the torn and crumpled fragments of a bar code label. The system hesitated for a few seconds, then responded with a pleasant blip sound. He smiled at me in triumph. ``Virtually indestructible.''
I was visiting the research laboratories of Symbol Technologies, of Bohemia NY, the world's leading manufacturer of bar code scanning equipment. Next time you are in the checkout line at a grocery store, check to see what type of scanning equipment they are using. Likely it will say Symbol on the housing.
Although we take bar codes for granted, there is a surprising amount of technology behind them. Bar codes exist primarily because conventional optical character recognition (OCR) systems are not sufficiently reliable for inventory operations. The bar code symbology familiar to us on each box of cereal or pack of gum encodes a ten-digit number with sufficient error correction such that it is virtually impossible to scan the wrong number, even if the can is upside-down or dented. Occasionally, the cashier won't be able to get a label to scan at all, but once you hear that blip you know it was read correctly.
The ten-digit capacity of conventional bar code labels means that there is only room to store a single ID number in a label. Thus any application of supermarket bar codes must have a database mapping 11141-47011 to a particular size and brand of soy sauce. The holy grail of the bar code world has long been the development of higher-capacity bar code symbologies that can store entire documents, yet still be read reliably. Largely through the efforts of Theo Pavlidis and Ynjiun Wang at Stony Brook [PSW92], Symbol Technologies was ready to introduce the first such product.

Figure: A two-dimensional bar-code label of the Gettysburg Address using PDF-417
``PDF-417 is our new, two-dimensional bar code symbology,'' Ynjiun explained.
A sample label is shown in Figure ![]() .
.
``How much data can you fit in a typical one-inch square label?'' I asked him.
``It depends upon the level of error correction we use, but about 1,000 bytes. That's enough for a small text file or image,'' he said.
``Interesting.
You will probably want to use some data compression technique
to maximize the amount of text you can store in a label.''
See Section ![]() for a discussion of standard
data compression algorithms.
for a discussion of standard
data compression algorithms.
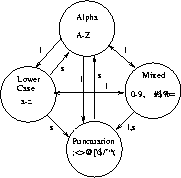
Figure: Mode switching in PDF-417
``We do incorporate a data compaction method,'' he explained. ``We figure there are several different types of files our customers will want to use our labels for. Some files will be all in uppercase letters, while others will use mixed-case letters and numbers. We provide four different text modes in our code, each with a different subset of ASCII characters available. So long as we stay within a mode, we can describe each character using only five bits. When we have to switch modes, we issue a mode switch command first (taking an extra five bits) and then the new code.''
``I see. So you designed the mode character sets to try to minimize the
number of mode switch operations on typical text files.''
The modes are illustrated in Figure ![]() .
.
``Right. We put all the digits in one mode and all the punctuation characters in another. We also included both mode shift and mode latch commands. In a mode shift, we switch into a new mode just for the next character, say to produce a punctuation mark. This way, we don't pay a cost for returning back to text mode after a period. Of course, we can also latch permanently into a different mode if we will be using a run of several characters from there.''
``Wow!'' I said. ``With all of this mode switching going on, there must be many different ways to encode any given text as a label. How do you find the smallest such encoding.''
``We use a greedy-type algorithm. We look a few characters ahead and then decide which mode we would be best off in. It works fairly well.''
I pressed him on this. ``How do you know it works fairly well? There might be significantly better encodings that you are simply not finding.''
``I guess I don't know. But it's probably NP-complete to find the optimal coding.'' Ynjiun's voice trailed off. ``Isn't it?''
I started to think. Every encoding started in a given mode and consisted of a sequence of intermixed character codes and mode shift/latch operations. At any given position in the text, we could output the next character code (if it was available in our current mode) or decide to shift. As we moved from left to right through the text, our current state would be completely reflected by our current character position and current mode state. For a given position/mode pair, we would have been interested in the cheapest way of getting there, over all possible encodings getting to this point....
My eyes lit up so bright they cast shadows on the walls.
``The optimal encoding for any given text in PDF-417 can be found using
dynamic programming.
For each possible mode ![]() and each character
position
and each character
position ![]() , we will maintain the cheapest
encoding found of the string to the left of i ending in mode m.
From each mode/position, we can either match, shift, or latch,
so there are only few possible operations to consider.
Each of the 4n cells can be filled in constant time, so it takes time
linear in the length of the string to find the optimal encoding.''
, we will maintain the cheapest
encoding found of the string to the left of i ending in mode m.
From each mode/position, we can either match, shift, or latch,
so there are only few possible operations to consider.
Each of the 4n cells can be filled in constant time, so it takes time
linear in the length of the string to find the optimal encoding.''
Ynjiun was skeptical, but he encouraged us to implement an optimal encoder. A few complications arose due to weirdnesses of PDF-417 mode switching, but my student Yaw-Ling Lin rose to the challenge. Symbol compared our encoder to theirs on 13,000 labels and concluded that dynamic programming lead to an 8% tighter encoding on average. This was significant, because no one wants to waste 8% of their potential storage capacity, particularly in an environment where the capacity is only a few hundred bytes. For certain applications, this 8% margin permitted one bar code label to suffice where previously two had been required. Of course, an 8% average improvement meant that it did much better than that on certain labels. While our encoder took slightly longer to run than the greedy encoder, this was not significant, since the bottleneck would be the time needed to print the label, anyway.
Our observed impact of replacing a heuristic solution with the global optimum is probably typical of most applications. Unless you really botch your heuristic, you are probably going to get a decent solution. But replacing it with an optimal result usually gives a small but non-trivial improvement, which can have pleasing consequences for your application.