The war story of Section ![]() reported how we used advanced data structures to simulate a new method
for sequencing DNA.
Our method, interactive sequencing by hybridization (SBH),
involved building arrays of specific oligonucleotides
on demand.
Although the simulation results were very promising to us,
most biologists we encountered were suspicious.
They needed to see our technique proven in the lab before they would
take it seriously.
reported how we used advanced data structures to simulate a new method
for sequencing DNA.
Our method, interactive sequencing by hybridization (SBH),
involved building arrays of specific oligonucleotides
on demand.
Although the simulation results were very promising to us,
most biologists we encountered were suspicious.
They needed to see our technique proven in the lab before they would
take it seriously.
But we got lucky.
A biochemist at Oxford University,
got interested in our
technique, and moreover he
had in his laboratory the equipment we needed to test it out.
The Southern Array Maker [Sou96], manufactured
by Beckman Instruments, could prepare discrete oligonucleotide sequences
in 64 parallel rows across a
polypropylene substrate.
The device constructs arrays by appending single characters to each
cell along specific rows and columns of arrays.
Figure ![]() shows how to construct an array of all
shows how to construct an array of all
![]() purine (A or G) 4-mers by building the prefixes along
rows and the suffixes along columns.
This technology provided an ideal environment for testing the feasibility
of interactive
SBH in a laboratory, because with proper programming it gave
an inexpensive way to fabricate a wide variety of oligonucleotide arrays
on demand.
purine (A or G) 4-mers by building the prefixes along
rows and the suffixes along columns.
This technology provided an ideal environment for testing the feasibility
of interactive
SBH in a laboratory, because with proper programming it gave
an inexpensive way to fabricate a wide variety of oligonucleotide arrays
on demand.
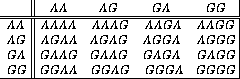
Figure: A prefix-suffix array of all purine 4-mers.
But we had to provide the proper programming. Fabricating complicated arrays requires solving a difficult combinatorial problem. We were given as input a set S of n strings (representing oligonucleotides) to fabricate an array (where m=64 on the Southern apparatus). We had to produce a schedule of row and column commands to realize the set of strings S. We proved that the problem of designing dense arrays was NP-complete, but that didn't really matter. My student Ricky Bradley and I had to solve it anyway.
``If it's hard, it's hard. We are going to have to use a heuristic,'' I told him. ``So how do we model this problem?''
``Well, for each string we can identify the possible prefix and suffix pairs that will realize it. For example, the string `ACC' can be realized in four different ways: prefix `' and suffix `ACC', prefix `A' and suffix `CC', prefix `AC' and suffix `C', or prefix `ACC' and suffix `'. We seek the smallest set of prefixes and suffixes that together realize all the given strings,'' Ricky said.
``Good. This gives us a natural representation for simulated annealing. The state space will consist of all possible subsets of prefixes and suffixes. The natural transitions between states might include inserting or deleting strings from our subsets, or swapping a pair in or out.''
``What's a good cost function?'' he asked.
``Well, we need as small an array as possible that covers all the strings. How about something like the maximum of number of rows (prefixes) or columns (suffixes) used in our array, plus the number of strings from S that are not yet covered. Try it and let's see what happens.''
Ricky went off and implemented a simulated annealing program along these lines. Printing out the state of the solution each time a transition was accepted, it was fun to watch. Starting from a random solution, the program quickly kicked out unnecessary prefixes and suffixes, and the array began shrinking rapidly in size. But after several hundred iterations, progress started to slow. A transition would knock out an unnecessary suffix, wait a while, then add a different suffix back again. After a few thousand iterations, no real improvement was happening.
``The program doesn't seem to recognize when it is making progress. The evaluation function only gives credit for minimizing the larger of the two dimensions. Why not add a term to give some credit to the other dimension.''
Ricky changed the evaluation function, and we tried again. This time, the program did not hesitate to improve the shorter dimension. Indeed, our arrays started to be skinny rectangles instead of squares.
``OK. Let's add another term to the evaluation function to give it points for being roughly square.''
Ricky tried again. Now the arrays were the right shape, and progress was in the right direction. But the progress was slow.
``Too many of the prefix/suffix insertion moves don't really seem to affect many strings. Maybe we should skew the random selections so that the important prefix/suffixes get picked more often.''
Ricky tried again, Now it converged faster, but sometimes it still got stuck. We changed the cooling schedule. It did better, but was it doing well? Without a lower bound knowing how close we were to optimal, it couldn't really tell how good our solution was. We tweaked and tweaked until our program stopped improving.
Our final solution refined the initial array by applying the following random moves:
A standard annealing schedule was used, with an exponentially decreasing temperature (dependent upon the problem size) and a temperature-dependent Boltzmann criterion for accepting states that have higher costs. Our final cost function was defined as
![]()
where max is the size of the maximum chip dimension, min is the size of
the minimum chip dimension, , and ![]() is the
number of strings in S currently on the chip.
is the
number of strings in S currently on the chip.
Careful analysis of successful moves over the course of the annealing process suggested a second phase of annealing to speed convergence. Once the temperature reaches a predetermined cutoff point, the temperature schedule was changed to force the temperature to decrease more rapidly, and the probability distribution for choosing moves was altered to include only swap, add, and delete, with preference given to swap moves. This modification sped up late convergence, which had been slower than it was in the early stages of the annealing process.
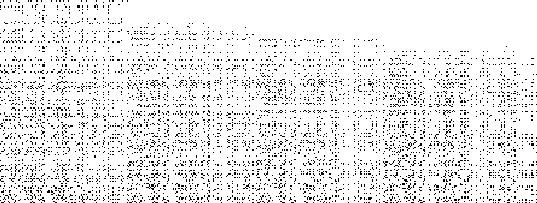
Figure: Compression of the HIV array by simulated annealing - after 0, 500, 1,000, and 5,750 iterations
How well did we do?
As reported in our paper [BS97],
Figure ![]() shows the convergence of a custom array
consisting of the 5,716 unique 7-mers of the HIV-virus.
Figure
shows the convergence of a custom array
consisting of the 5,716 unique 7-mers of the HIV-virus.
Figure ![]() shows snapshots of the state of the chip at four points
during the annealing process (0, 500, 1,000, and the final chip at 5,750
iterations). Black pixels represent the first occurrence of an HIV 7-mer,
while white pixels represent either duplicated HIV 7-mers or strings not in
the HIV input set. The final chip size here is
shows snapshots of the state of the chip at four points
during the annealing process (0, 500, 1,000, and the final chip at 5,750
iterations). Black pixels represent the first occurrence of an HIV 7-mer,
while white pixels represent either duplicated HIV 7-mers or strings not in
the HIV input set. The final chip size here is ![]() ,
quite an improvement over
the initial size of
,
quite an improvement over
the initial size of ![]() .
It took about fifteen minutes' worth of computation on a desktop workstation
to complete the optimization, which was perfectly acceptable for the
application.
.
It took about fifteen minutes' worth of computation on a desktop workstation
to complete the optimization, which was perfectly acceptable for the
application.
But how well did we do? Since simulated annealing is only a heuristic, we really don't know how close to optimal our solution is. I think we did pretty well, but I can't really be sure. In conclusion, simulated annealing can be the right way to handle complex optimization problems. However, to get the best results, expect to spend more time tweaking and refining your program than you did in writing it in the first place. This is dirty work, but sometimes you have to do it.