``It takes five minutes just to read the data. We will never have time to make it do something interesting.''
The young graduate student was bright and eager, but green to the power of data structures. She would soon come to appreciate the power.
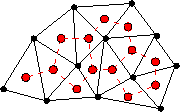
Figure: The dual graph (dashed lines) of a triangulation
As described in a previous war
story (see Section ![]() ),
we were experimenting with algorithms for extracting triangular strips
for the fast rendering of triangulated surfaces.
The task of finding a small number of strips that cover each triangle
in a mesh could be modeled as a graph problem, where the graph has
a vertex for every triangle of the mesh, and there is an
edge between every pair of vertices representing adjacent triangles.
This dual graph representation
of the planar subdivision representing the triangulation
(see Figure
),
we were experimenting with algorithms for extracting triangular strips
for the fast rendering of triangulated surfaces.
The task of finding a small number of strips that cover each triangle
in a mesh could be modeled as a graph problem, where the graph has
a vertex for every triangle of the mesh, and there is an
edge between every pair of vertices representing adjacent triangles.
This dual graph representation
of the planar subdivision representing the triangulation
(see Figure ![]() ) captures all the information about the
triangulation needed to partition it into triangle strips.
) captures all the information about the
triangulation needed to partition it into triangle strips.
The first step in crafting a program that constructs a good set of strips was to build the dual graph of the triangulation. This I sent the student off to do. A few days later, she came back and announced that it took over five CPU minutes just to construct this dual graph of an object with a few thousand triangles.
``Nonsense!'' I proclaimed. ``You must be doing something very wasteful in building the graph. What format is the data in?''
``Well, it starts out with a list of the 3D-coordinates of the vertices used in the model and then follows with a list of triangles. Each triangle is described by a list of three indices into the vertex coordinates. Here is a small example:''
VERTICES 4
0.000000 240.000000 0.000000
204.000000 240.000000 0.000000
204.000000 0.000000 0.000000
0.000000 0.000000 0.000000
TRIANGLES 2
0 1 3
1 2 3
``I see. So the first triangle must use all but the third point, since all the indices start from zero. The two triangles must share an edge formed by points 1 and 3.''
``Yeah, that's right,'' she confirmed.
``OK. Now tell me how you built your dual graph from this file.''
``Well, I can pretty much ignore the vertex information, once I know how many vertices there will be. The geometric position of the points doesn't affect the structure of the graph. My dual graph is going to have as many vertices as the number of triangles. I set up an adjacency list data structure with that many vertices. As I read in each triangle, I compare it to each of the others to check whether it has two numbers in common. Whenever it does, I add an edge from the new triangle to this one.''
I started to sputter. ``But that's your problem right there! You are comparing each triangle against every other triangle, so that constructing the dual graph will be quadratic in the number of triangles. Reading in the input graph should take linear time!''
``I'm not comparing every triangle against every other triangle. On average, it only tests against half or a third of the triangles.''
``Swell. But that still leaves us with an ![]() algorithm.
That is much too slow.''
algorithm.
That is much too slow.''
She stood her ground. ``Well, don't just complain. Help me fix it!''
Fair enough. I started to think. We needed some quick method to screen away most of the triangles that would not be adjacent to the new triangle (i,j,k). What we really needed was just a list of all the triangles that go through each of the points i, j, and k. Since each triangle goes through three points, the average point is incident on three triangles, so this would mean comparing each new triangle against fewer than ten others, instead of most of them.
``We are going to need a data structure consisting of an array with one element for every vertex in the original data set. This element is going to be a list of all the triangles that pass through that vertex. When we read in a new triangle, we will look up the three relevant lists in the array and compare each of these against the new triangle. Actually, only two of the three lists are needed, since any adjacent triangle will share two points in common. For anything sharing two vertices, we will add an adjacency to our graph. Finally, we will add our new triangle to each of the three affected lists, so they will be updated for the next triangle read.''
She thought about this for a while and smiled. ``Got it, Chief. I'll let you know what happens.''
The next day she reported that the graph could be built in
seconds,
even for much larger models.
From here, she went on to build a successful program for extracting
triangle strips, as reported in Section ![]() .
.
The take-home lesson here is that even elementary problems like initializing data structures can prove to be bottlenecks in algorithm development. Indeed, most programs working with large amounts of data have to run in linear or almost linear time. With such tight performance demands, there is no room to be sloppy. Once you focus on the need for linear-time performance, an appropriate algorithm or heuristic can usually be found to do the job.