
Figure: (a) A triangulated model of a dinosaur
(b) Several triangle strips in the model
The most common type of geometric model used for computer graphics describes
the geometry of the object as a triangulated surface,
as shown in Figure ![]() a.
High-performance rendering engines have special hardware for rendering
and shading triangles.
This hardware is so fast that the bottleneck of rendering is
simply feeding the structure of the triangulation into the hardware engine.
a.
High-performance rendering engines have special hardware for rendering
and shading triangles.
This hardware is so fast that the bottleneck of rendering is
simply feeding the structure of the triangulation into the hardware engine.
Although each triangle can be described by specifying its three endpoints
and any associated shading/normal information, an alternative
representation is more efficient.
Instead of specifying each triangle in isolation, suppose that we
partition the
triangles into strips of adjacent triangles and walk along the strip,
as shown in Figure ![]() (b).
Since each triangle shares two vertices in common with its neighbors, we
save the cost of retransmitting the two extra vertices and any associated
normals.
To make the description of the triangles unambiguous,
the Silicon Graphics triangular-mesh
renderer OpenGL assumes that all turns alternate from left to right
(as shown in Figure
(b).
Since each triangle shares two vertices in common with its neighbors, we
save the cost of retransmitting the two extra vertices and any associated
normals.
To make the description of the triangles unambiguous,
the Silicon Graphics triangular-mesh
renderer OpenGL assumes that all turns alternate from left to right
(as shown in Figure ![]() ).
).
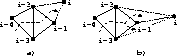
Figure: Partitioning a triangular mesh into strips: (a) with left-right turns
(b) with the flexibility of arbitrary turns
The problem of finding a small number of strips that cover each triangle
in a mesh can be thought of as a graph problem, where this graph has
a vertex for every triangle of the mesh, and there is an
edge between every pair of vertices representing adjacent triangles.
This dual graph representation
of the planar subdivision representing the triangulation
(see Section ![]() ) captures all the information about the
triangulation needed to partition it into triangle strips.
Section
) captures all the information about the
triangulation needed to partition it into triangle strips.
Section ![]() describes our experiences constructing the
graph from the triangulation.
describes our experiences constructing the
graph from the triangulation.
Once we had the dual graph available, the project could begin in earnest.
We sought to partition the vertices of the dual graph into as few paths
or strips as possible. Partitioning it into one path implied that we had discovered
a Hamiltonian path,
which by definition visits each vertex exactly once.
Since finding a Hamiltonian path was NP-complete
(see Section ![]() ), we knew not to look for an
optimal algorithm, but to concentrate instead on heuristics.
), we knew not to look for an
optimal algorithm, but to concentrate instead on heuristics.
It is always best to start with simple heuristics before trying more complicated ones, because simple might well suffice for the job. The most natural heuristic for strip cover would be to start from an arbitrary triangle and then do a left-right walk from there until the walk ends, either by hitting the boundary of the object or a previously visited triangle. This heuristic had the advantage that it would be fast and simple, although there could be no reason to suspect that it should find the smallest possible set of left-right strips for a given triangulation.
A heuristic more likely to result in a small number of strips would be greedy. Greedy heuristics always try to grab the best possible thing first. In the case of the triangulation, the natural greedy heuristic would find the starting triangle that yields the longest left-right strip, and peel that one off first.
Being greedy also does not guarantee you the best possible solution, since the first strip you peel off might break apart a lot of potential strips we would have wanted to use later. Still, being greedy is a good rule of thumb if you want to get rich. Since removing the longest strip would leave the fewest number of triangles for later strips, it seemed reasonable that the greedy heuristic would out-perform the naive heuristic.
But how much time does it take to find the largest strip to peel off
next?
Let k be the length of the walk possible from an average vertex.
Using the simplest possible implementation, we could walk from each of the
n vertices per iteration in order to find the largest remaining strip
to report in ![]() time.
With the total number of strips roughly equal to n/k,
this yields an
time.
With the total number of strips roughly equal to n/k,
this yields an ![]() -time
implementation, which would be hopelessly slow on a typical model of 20,000
triangles.
-time
implementation, which would be hopelessly slow on a typical model of 20,000
triangles.
How could we speed this up? It seems wasteful to rewalk from each triangle after deleting a single strip. We could maintain the lengths of all the possible future strips in a data structure. However, whenever we peel off a strip, we would have to update the lengths of all the other strips that will be affected. These strips will be shortened because they walked through a triangle that now no longer exists. There are two aspects of such a data structure:
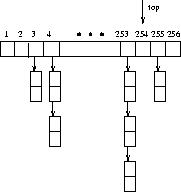
Figure: A bounded height priority queue for triangle strips
To update a queue entry associated with a triangle, we needed to be able to quickly find where it was. This meant that we also needed a ...
Although there were various other complications, such as quickly recalculating the length of the strips affected by the peeling, the key idea needed to obtain better performance was to use the priority queue. Run time improved by several orders of magnitude after employing these data structures.
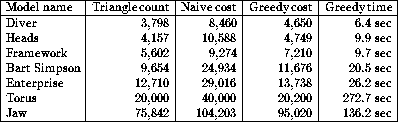
Figure: A comparison of the naive versus greedy heuristics for several
triangular meshes
How much better did the greedy heuristic do than the naive heuristic?
Consider the table in Figure ![]() .
In all cases, the greedy heuristic led to a set of strips that cost less,
as measured by the total size of the strips.
The savings ranged from about 10% to 50%, quite remarkable, since the
greatest possible improvement (going from three vertices per
triangle down to one)
could yield a savings of only 66.6%.
.
In all cases, the greedy heuristic led to a set of strips that cost less,
as measured by the total size of the strips.
The savings ranged from about 10% to 50%, quite remarkable, since the
greatest possible improvement (going from three vertices per
triangle down to one)
could yield a savings of only 66.6%.
After implementing the greedy heuristic with our priority queue
data structure, our complete algorithm ran in ![]() time,
where n is the number
of triangles and k is the length of the average strip.
Thus the torus, which consisted of a small number of very long strips,
took longer than the jaw, even though the latter contained over three times
as many triangles.
time,
where n is the number
of triangles and k is the length of the average strip.
Thus the torus, which consisted of a small number of very long strips,
took longer than the jaw, even though the latter contained over three times
as many triangles.
There are several lessons to be gleaned from this story.
First, whenever we are working with a large enough data set, only linear or close to
linear algorithms (say ![]() ) are likely to be fast enough.
Second, choosing the right data structure is often the key to getting the
time complexity down to this point.
Finally, using a greedy or somewhat smarter heuristic over the naive approach
is likely to significantly improve the quality of the results.
How much the improvement is likely to be can be determined only
by experimentation.
Our final, optimized triangle strip program is described in
[ESV96].
) are likely to be fast enough.
Second, choosing the right data structure is often the key to getting the
time complexity down to this point.
Finally, using a greedy or somewhat smarter heuristic over the naive approach
is likely to significantly improve the quality of the results.
How much the improvement is likely to be can be determined only
by experimentation.
Our final, optimized triangle strip program is described in
[ESV96].