Suppose that three workers are given the task of scanning through a shelf of books in search of a given piece of information. To get the job done fairly and efficiently, the books are to be partitioned among the three workers. To avoid the need to rearrange the books or separate them into piles, it would be simplest to divide the shelf into three regions and assign each region to one worker.
But what is the fairest way to divide the shelf up? If each book is the same length, say 100 pages, the job is pretty easy. Just partition the books into equal-sized regions,
![]()
so that everyone has 300 pages to deal with.
But what if the books are not the same length? Suppose we used the same partition when the book sizes looked like this:
![]()
I, for one, would volunteer to take the first section, with only 600 pages to scan, instead of the last one, with 2,400 pages. The fairest possible partition for this shelf would be
![]()
where the largest job is only 1,700 pages and the smallest job 1,300.
In general, we have the following problem:
Input: A given arrangement S of non-negative numbers ![]() and an integer k.
and an integer k.
Output: Partition S into k ranges, so as to minimize the maximum sum
over all the ranges.
This so-called linear partition problem arises often in
parallel processing, since we seek to balance the work done across
processors so as to minimize the total elapsed run time.
Indeed, the war story of Section ![]() revolves around
a botched solution to this problem.
revolves around
a botched solution to this problem.
Stop for a few minutes and try to find an algorithm to solve the linear partition problem.
Instead, consider a recursive, exhaustive search approach to solving
this problem.
Notice that the kth partition starts right after we placed the (k-1)st
divider.
Where can we place this last divider?
Between the ith and (i+1)st elements for some i, where ![]() .
What is the cost of this?
The total cost will be the larger of two quantities,
(1) the cost of the last partition
.
What is the cost of this?
The total cost will be the larger of two quantities,
(1) the cost of the last partition ![]() and
(2) the cost of the largest partition cost formed to the left of i.
What is the size of this left partition?
To minimize our total, we would want to use the k-2 remaining dividers
to partition the elements
and
(2) the cost of the largest partition cost formed to the left of i.
What is the size of this left partition?
To minimize our total, we would want to use the k-2 remaining dividers
to partition the elements ![]() as equally
as possible.
This is a smaller instance of the same problem, and hence can be
solved recursively!
as equally
as possible.
This is a smaller instance of the same problem, and hence can be
solved recursively!
Therefore, let us define M[n,k] to be the minimum possible cost over all
partitionings of ![]() into k ranges, where the cost
of a partition is the
largest sum of elements in one of its parts.
Thus defined, this function can be evaluated:
into k ranges, where the cost
of a partition is the
largest sum of elements in one of its parts.
Thus defined, this function can be evaluated:
![]()
with the natural basis cases of
![]()
![]()
By definition, this recurrence must return the size of the optimal partition. But how long does it take? If we evaluate the recurrence without storing partial results, we will be doomed to spend exponential time, repeatedly recalculating the same quantities. However, by storing the computed values and looking them up as needed, we can save an enormous amount of time.
How long does it take to compute this when we store the partial results?
Well, how many results are computed?
A total of ![]() cells exist in the table.
How much time does it take to compute the result M[n',k']?
Well, calculating this quantity involves finding the minimum of n'
quantities, each of which is the maximum of the table lookup and a sum
of at most n' elements.
If filling each of k n boxes takes at most
cells exist in the table.
How much time does it take to compute the result M[n',k']?
Well, calculating this quantity involves finding the minimum of n'
quantities, each of which is the maximum of the table lookup and a sum
of at most n' elements.
If filling each of k n boxes takes at most ![]() time per box, the
total recurrence can be computed in
time per box, the
total recurrence can be computed in ![]() time.
time.
To complete the implementation, we must specify the boundary conditions of
the recurrence relation and an order to evaluate it in.
These boundary conditions always settle the smallest possible values for
each of the arguments of the recurrence.
For this problem, the smallest reasonable value of the first argument is n=1,
meaning that the first partition consists of a single element.
We can't create a first partition smaller than ![]() regardless of how many
dividers are used.
The smallest reasonable value of the second argument is k=1,
implying that we do not partition S at all.
regardless of how many
dividers are used.
The smallest reasonable value of the second argument is k=1,
implying that we do not partition S at all.
The evaluation order computes the smaller values before the bigger values, so that each evaluation has what it needs waiting for it. Full details are provided in the pseudocode below:
Partition[S,k]
(* compute prefix sums:
*)
p[0] = 0
for i=1 to n do
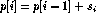
(* initialize boundary conditions *)
for i=1 to n do M[i,1] = p[i]
for i=1 to k do
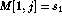
(* evaluate main recurrence *)
for i=2 to n do
for j = 2 to k do
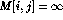
for x = 1 to i-1 do
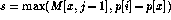
if (M[i,j] > ) then
M[i,j] =
D[i,j] = x
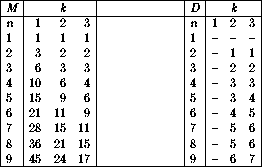
Figure: Dynamic programming matrices M and D in
partitioning ![]()
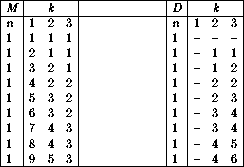
Figure: Dynamic programming matrices M and D in
partitioning ![]()
The implementation above in fact runs faster than advertised.
Our original analysis assumed that it took ![]() time to update each cell of
the matrix.
This is because we selected the best of up to n possible points to place
the divider, each of which requires the sum of up to n possible terms.
In fact, it is easy to avoid the need to compute these sums by
storing the set of n prefix sums
time to update each cell of
the matrix.
This is because we selected the best of up to n possible points to place
the divider, each of which requires the sum of up to n possible terms.
In fact, it is easy to avoid the need to compute these sums by
storing the set of n prefix sums ![]() ,
since
,
since ![]() .
This enables us to evaluate the recurrence in linear time per cell,
yielding an
.
This enables us to evaluate the recurrence in linear time per cell,
yielding an ![]() algorithm.
algorithm.
By studying the recurrence relation and the dynamic programming matrices
of Figures ![]() and
and ![]() ,
you should be able to convince yourself
that the final value of M(n,k) will be the cost of the largest range
in the optimal partition.
However, what good is that?
For most applications, what we need is the actual
partition that does the job.
Without it, all we are left with is
a coupon for a great price on an out-of-stock item.
,
you should be able to convince yourself
that the final value of M(n,k) will be the cost of the largest range
in the optimal partition.
However, what good is that?
For most applications, what we need is the actual
partition that does the job.
Without it, all we are left with is
a coupon for a great price on an out-of-stock item.
The second matrix, D, is used to reconstruct the optimal partition. Whenever we update the value of M[i,j], we record which divider position was required to achieve that value. To reconstruct the path used to get to the optimal solution, we work backward from D[n,k] and add a divider at each specified position. This backwards walking is best achieved by a recursive subroutine:
ReconstructPartition(S,D,n,k)
If (k = 1) then print the first partition
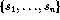
else
ReconstructPartition(S,D,D[n,k],k-1)
Print the kth partition {
}
It is important to catch the distinction between storing the value of a cell and what decision/move it took to get there. The latter is not used in the computation but is presumably the real thing that you are interested in. For most of the examples in this chapter, we will not worry about reconstructing the answer. However, study this example closely to ensure that you know how to obtain the winning configuration when you need it.