8.2-3 Argue that insertion sort is better than Quicksort for sorting checks
In insertion sort, the cost of each insertion is the number of items
which we have to jump over.
In the check example, the expected number of moves per items is small,
say c.
We win if ![]() .
.
8.3-1 Why do we analyze the average-case performance of a randomized algorithm, instead of the worst-case?
8.3-2 How many calls are made to Random in randomized quicksort in the best and worst cases?
The number of partitions is ![]() in any run of quicksort!!
in any run of quicksort!!
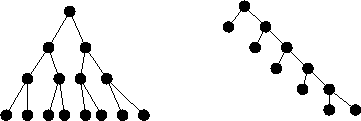
The reason - any binary tree with n leaves has n-1 internal nodes, each of which corresponds to a call to partition in the quicksort recursion tree.
Elementary Data Structures
``Mankind's progress is measured by the number of things we can do without thinking.''
Elementary data structures such as stacks, queues, lists, and heaps will be the ``of-the-shelf'' components we build our algorithm from. There are two aspects to any data structure:
The fact that we can describe the behavior of our data structures in terms of abstract operations explains why we can use them without thinking, while the fact that we have different implementation of the same abstract operations enables us to optimize performance.
Stacks and Queues
Sometimes, the order in which we retrieve data is independent of its content, being only a function of when it arrived.
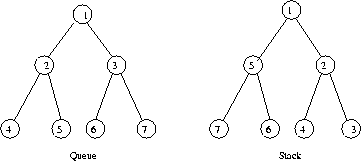
A stack supports last-in, first-out operations: push and pop.
A queue supports first-in, first-out operations: enqueue and dequeue.
A deque is a double ended queue and supports all four operations: push, pop, enqueue, dequeue.
Lines in banks are based on queues, while food in my refrigerator is treated as a stack.
Both can be used to traverse a tree, but the order is completely different.
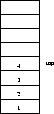
Stack Implementation
Although this implementation uses an array, a linked list would eliminate the need to declare the array size in advance.
STACK-EMPTY(S)
if top[S] = 0
then return TRUE
else return FALSE
PUSH(S, x)
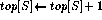
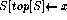
POP(S)
if STACK-EMPTY(S)
then error ``underflow''
else
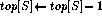
return S[top[S] + 1]
Queue Implementation
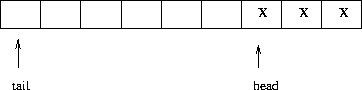
A circular queue implementation requires pointers to the head and tail elements, and wraps around to reuse array elements.
ENQUEUE(Q, x)
Q[tail[Q]]
x
if tail[Q] = length[Q]
then tail[Q]
else tail[Q]
DEQUEUE(Q)
x = Q[head[Q]]
if head[Q] = length[Q]
then head[Q] = 1
else head[Q] = head[Q] + 1
return x
A list-based implementation would eliminate the possibility of overflow.
All are O(1) time operations.
Dynamic Set Operations
Perhaps the most important class of data structures maintain a set of items, indexed by keys.
There are a variety of implementations of these dictionary operations, each of which yield different time bounds for various operations.
Pointer Based Implementation
We can maintain a dictionary in either a singly or doubly linked list.
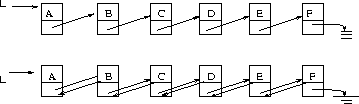
Since the extra big-Oh costs of doubly-linkly lists is zero, we will usually assume they are, although it might not be necessary.
Singly linked to doubly-linked list is as a Conga line is to a Can-Can line.
Array Based Sets
Unsorted Arrays
Sorted Arrays
What are the costs for a heap?
Unsorted List Implementation
LIST-SEARCH(L, k)
x = head[L]
while x <> NIL and key[x] <> k
do x = next[x]
return x
Note: the while loop might require two lines in some programming languages.
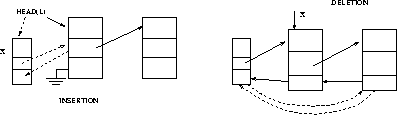
LIST-INSERT(L, x)
next[x] = head[L]
if head[L] <> NIL
then prev[head[L]] = x
head[L] = x
prev[x] = NIL
LIST-DELETE(L, x)
if prev[x] <> NIL
then next[prev[x]] = next[x]
else head[L] = next[x]
if next[x] <> NIL
then prev[next[x]] = prev[x]
Sentinels
Boundary conditions can be eliminated using a sentinel element which doesn't go away.
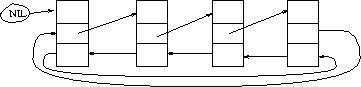
LIST-SEARCH'(L, k)
x = next[nil[L]]
while x <> NIL[L] and key[x] <> k
do x = next[x]
return x
LIST-INSERT'(L, x)
next[x] = next[nil[L]]
prev[next[nil[L]]] = x
next[nil[L]] = x
prev[x] = NIL[L]
LIST-DELETE'(L, x)
next[prev[x]] <> next[x]
next[prev[x]] = prev[x]
Hash Tables
Hash tables are a very practical way to maintain a dictionary. As with bucket sort, it assumes we know that the distribution of keys is fairly well-behaved.
The idea is simply that looking an item up in an array is ![]() once you have its index.
A hash function is a mathematical function which maps keys to integers.
once you have its index.
A hash function is a mathematical function which maps keys to integers.
In bucket sort, our hash function mapped the key to a bucket based on the first letters of the key. ``Collisions'' were the set of keys mapped to the same bucket.
If the keys were uniformly distributed, then each bucket contains very few keys!
The resulting short lists were easily sorted, and could just as easily be searched!
Hash Functions
It is the job of the hash function to map keys to integers. A good hash function:
The first step is usually to map the key to a big integer, for example
![]()
This large number must be reduced to an integer whose size is between 1 and the size of our hash table.
One way is by
![]() , where M is best a large prime not too close to
, where M is best a large prime not too close to ![]() ,
which would just mask off the high bits.
,
which would just mask off the high bits.
This works on the same principle as a roulette wheel!
Good and Bad Hash functions
The first three digits of the Social Security Number
The Birthday Paradox
No matter how good our hash function is, we had better be prepared for collisions, because of the birthday paradox.

![]()
When m = 366, this probability sinks below 1/2 when N = 23 and
to almost 0 when ![]() .
.
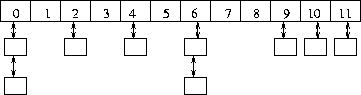
Collision Resolution by Chaining
The easiest approach is to let each element in the hash table be a pointer to a list of keys.
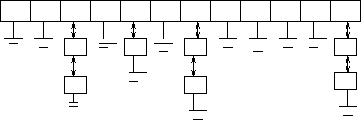
Chaining is easy, but devotes a considerable amount of memory to pointers, which could be used to make the table larger. Still, it is my preferred method.
Open Addressing
We can dispense with all these pointers by using an implicit reference derived from a simple function:
The reason for using a more complicated science is to avoid long runs from similarly hashed keys.
Deletion in an open addressing scheme is ugly, since removing one element can break a chain of insertions, making some elements inaccessible.
Performance on Set Operations
With either chaining or open addressing:
Pragmatically, a hash table is often the best data structure to maintain a dictionary. However, we will not use it much in proving the efficiency of our algorithms, since the worst-case time is unpredictable.
The best worst-case bounds come from balanced binary trees, such as red-black trees.