7.1-2: Show that an n-element heap has height ![]() .
.
The height is defined as the number of edges in the longest simple path from the root.
Thus the height increases only when ![]() , or in other words
when
, or in other words
when ![]() is an integer.
is an integer.
7.1-5 Is a reverse sorted array a heap?
In the array representation of a heap, the descendants of the ith element are the 2ith and (2i+1)th elements.
If A is sorted in reverse order, then ![]() implies
that
implies
that ![]() .
.
Since 2i > i and 2i+1 > i then
![]() and
and ![]() .
.
Thus by definition A is a heap!
Can we sort in better than ![]() ?
?
Any comparison-based sorting program can be thought of as defining a decision tree of possible executions.
Running the same program twice on the same permutation causes it to do exactly the same thing, but running it on different permutations of the same data causes a different sequence of comparisons to be made on each.
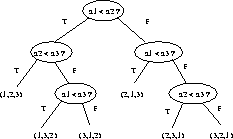
Once you believe this, a lower bound on the time complexity of sorting follows easily.
Since any two different permutations of n elements requires a different sequence of steps to sort, there must be at least n! different paths from the root to leaves in the decision tree, ie. at least n! different leaves in the tree.
Since only binary comparisons (less than or greater than) are used, the decision tree is a binary tree.
Since a binary tree of height h has at most ![]() leaves, we know
leaves, we know
![]() , or
, or ![]() .
.
By inspection ![]() , since the last n/2 terms of the product
are each greater than n/2.
By Sterling's approximation, a better bound is
, since the last n/2 terms of the product
are each greater than n/2.
By Sterling's approximation, a better bound is ![]() where e=2.718.
where e=2.718.
![]()
Non-Comparison-Based Sorting
All the sorting algorithms we have seen assume binary comparisons as the basic primative, questions of the form ``is x before y?''.
Suppose you were given a deck of playing cards to sort. Most likely you would set up 13 piles and put all cards with the same number in one pile.
A 2 3 4 5 6 7 8 9 10 J Q K
A 2 3 4 5 6 7 8 9 10 J Q K
A 2 3 4 5 6 7 8 9 10 J Q K
A 2 3 4 5 6 7 8 9 10 J Q K
With only a constant number of cards left in each pile, you can use insertion sort to order by suite and concatenate everything together.
If we could find the correct pile for each card in constant time, and each pile gets O(1) cards, this algorithm takes O(n) time.
Bucketsort
Suppose we are sorting n numbers from 1 to m, where we know the numbers are approximately uniformly distributed.
We can set up n buckets, each responsible for an interval of m/n numbers from 1 to m
If we use an array of buckets, each item gets mapped to the right bucket in O(1) time.
With uniformly distributed keys, the expected number of items per bucket is 1. Thus sorting each bucket takes O(1) time!
The total effort of bucketing, sorting buckets, and concatenating the sorted buckets together is O(n).
What happened to our ![]() lower bound!
lower bound!
We can use bucketsort effectively whenever we understand the distribution of the data.
However, bad things happen when we assume the wrong distribution.
Suppose in the previous example all the keys happened to be 1. After the bucketing phase, we have:
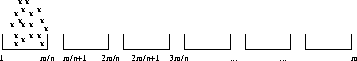
Problems like this are why we worry about the worst-case performance of algorithms!
Such distribution techniques can be used on strings instead of just numbers. The buckets will correspond to letter ranges instead of just number ranges.
The worst case ``shouldn't'' happen if we understand the distribution of our data.
Real World Distributions
Consider the distribution of names in a telephone book.
Either make sure you understand your data, or use a good worst-case or randomized algorithm!
The Shifflett's of Charlottesville
For comparison, note that there are seven Shifflett's (of various spellings) in the 1000 page Manhattan telephone directory.

Rules for Algorithm Design
The secret to successful algorithm design, and problem solving in general, is to make sure you ask the right questions. Below, I give a possible series of questions for you to ask yourself as you try to solve difficult algorithm design problems: