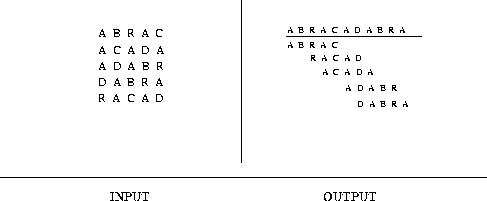
Input description: A set of strings ![]() .
.
Problem description: Find the shortest string S' that contains each element of S as a substring.
Discussion: Shortest common superstring arises in a variety of applications,
including sparse matrix compression.
Suppose we have an ![]() matrix with most of the elements being
zero.
We can partition each row into m/k runs of k elements each
and construct the shortest common superstring S' of these runs.
We now have reduced the problem to storing the superstring, plus
an
matrix with most of the elements being
zero.
We can partition each row into m/k runs of k elements each
and construct the shortest common superstring S' of these runs.
We now have reduced the problem to storing the superstring, plus
an ![]() array of pointers into the superstring denoting
where each of the runs starts.
Accessing a particular element M[i,j] still takes constant time,
but there is a space savings when |S| << mn.
array of pointers into the superstring denoting
where each of the runs starts.
Accessing a particular element M[i,j] still takes constant time,
but there is a space savings when |S| << mn.
Another application arises in DNA sequencing. It happens to be easy to sequence small fragments of DNA, say up to about 500 base pairs or characters. However, the real interest is in sequencing large molecules. The standard approach to large-scale, ``shotgun'' sequencing clones many copies of the target molecule, breaks them randomly into small fragments, sequences the fragments, and then proposes the shortest superstring of the fragments as the correct sequence. While it is an article of faith that the shortest superstring will be the most likely sequence, this seems to work reasonably well in practice.
Finding a superstring of all the substrings is not difficult, as we can simply concatenate them all together. It is finding the shortest such string that is problematic. Indeed, shortest common superstring remains NP-complete under all reasonable classes of strings.
The problem of finding the shortest common superstring can easily be
reduced to that of the traveling salesman problem
(see Section ![]() ).
Create an overlap graph G where vertex
).
Create an overlap graph G where vertex ![]() represents string
represents string ![]() .
Edge
.
Edge ![]() will have weight equal to the length of
will have weight equal to the length of ![]() minus the
overlap of
minus the
overlap of ![]() with
with ![]() .
The path visiting all the vertices of minimum total weight defines the
shortest common superstring.
The edge weights of this graph are not symmetric, after all,
the overlap of
.
The path visiting all the vertices of minimum total weight defines the
shortest common superstring.
The edge weights of this graph are not symmetric, after all,
the overlap of ![]() and
and ![]() is not the same as the overlap of
is not the same as the overlap of ![]() and
and ![]() .
Thus only programs capable of solving asymmetric TSPs
can be applied to this problem.
.
Thus only programs capable of solving asymmetric TSPs
can be applied to this problem.
The greedy heuristic is the standard approach to approximating
the shortest common superstring.
Find the pair of strings with the maximum number of characters of overlap.
Replace them by the merged string, and repeat until only one string remains.
Given the overlap graph above, this heuristic can be efficiently implemented
by inserting all of the edge weights
into a heap (see Section ![]() )
and then merging if the appropriate ends of the two strings have not yet be
used, which can be maintained with an array of Boolean flags.
)
and then merging if the appropriate ends of the two strings have not yet be
used, which can be maintained with an array of Boolean flags.
The potentially time-consuming part of this heuristic is in building
the overlap graph.
The brute-force approach to finding the maximum overlap of
two length-l strings takes ![]() , which must be
repeated
, which must be
repeated ![]() times.
Faster times are possible by appropriately using suffix trees (see
Section
times.
Faster times are possible by appropriately using suffix trees (see
Section ![]() ).
Build a tree containing all suffixes of all reversed strings of S.
String
).
Build a tree containing all suffixes of all reversed strings of S.
String ![]() overlaps with
overlaps with ![]() if a suffix of
if a suffix of ![]() matches a suffix
of the reverse of
matches a suffix
of the reverse of ![]() .
The longest overlap for each fragment can be found in time linear in its
length.
.
The longest overlap for each fragment can be found in time linear in its
length.
How well does the greedy heuristic perform? If we are unlucky with the input, the greedy heuristic can be fooled into creating a superstring that is at least twice as long as optimal. Usually, it will be a lot better in practice. It is known that the resulting superstring can never be more than 2.75 times optimal.
Building superstrings becomes more difficult with positive and negative substrings, where negative substrings cannot be substrings of the superstring. The problem of deciding whether any such consistent substring exists is NP-complete, unless you are allowed to add an extra character to the alphabet to use as a spacer.
Implementations: CAP (Contig Assembly Program) [Hua92] by Xiaoqiu Huang is a C language program supporting DNA shotgun sequencing by finding the shortest common superstring of a set of fragments. As to performance, CAP took 4 hours to assemble 1,015 fragments of a total of 252,000 characters on a Sun SPARCstation SLC. Certain parameters will need to be tweaked to make it accommodate non-DNA data. It is available by anonymous ftp from cs.mtu.edu in the pub/huang directory.
Notes: The shortest common superstring problem and its application to DNA shotgun assembly is ably surveyed in [Wat95]. Kececioglu and Myers [KM95] report on an algorithm for the more general version of shortest common superstring, where the strings may have errors. Their paper is recommended reading to anyone interested in fragment assembly.
Blum et al. [BJL ![]() 91] gave the first constant-factor
approximation algorithms for shortest common superstring, with a variation
of the greedy heuristic.
More recent research has beaten the constant down to 2.75, progress towards
the expected factor-two result.
91] gave the first constant-factor
approximation algorithms for shortest common superstring, with a variation
of the greedy heuristic.
More recent research has beaten the constant down to 2.75, progress towards
the expected factor-two result.
Related Problems: Suffix trees (see page ![]() ),
text compression (see page
),
text compression (see page ![]() ).
).