25.1-1
Give two more shortest path trees for the following graph:
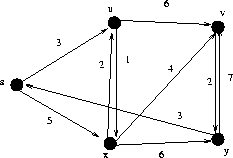
There are two choices for how to get to the third vertex x, both of which cost 5.
There are two choices for how to get to vertex v, both of which cost 9.
Lessons from the Backtracking contest
Winning Optimizations
Shortest Paths
Finding the shortest path between two nodes in a graph arises in many different applications:
Shortest Paths and Sentence Disambiguation
In our work on reconstructing text typed on an (overloaded) telephone keypad, we had to select which of many possible interpretations was most likely.
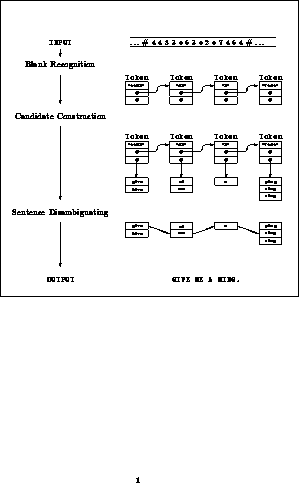
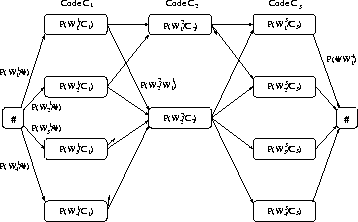
The final system worked extremely well - identifying over 99% of characters correctly based on grammatical and statistical constraints.
Dynamic programming (the Viterbi algorithm) can be used on the sentences to obtain the same results, by finding the shortest paths in the underlying DAG.
Finding Shortest Paths
In an unweighted graph, the cost of a path is just the number of edges on the shortest path, which can be found in O(n+m) time via breadth-first search.
In a weighted graph, the weight of a path between two vertices is the sum of the weights of the edges on a path.
BFS will not work on weighted graphs because sometimes visiting more edges can lead to shorter distance, ie. 1+1+1+1+1+1+1 < 10.
Note that there can be an exponential number of shortest paths between two nodes - so we cannot report all shortest paths efficiently.
Note that negative cost cycles render the problem of finding the shortest path meaningless, since you can always loop around the negative cost cycle more to reduce the cost of the path.
Thus in our discussions, we will assume that all edge weights are positive. Other algorithms deal correctly with negative cost edges.
Minimum spanning trees are uneffected by negative cost edges.
Dijkstra's Algorithm
We can use Dijkstra's algorithm to find the shortest path between any two vertices and t in G.
The principle behind Dijkstra's algorithm is that
if ![]() is the shortest path from to t, then
is the shortest path from to t, then
![]() had better be the shortest path from to x.
had better be the shortest path from to x.
This suggests a dynamic programming-like strategy, where we store the distance from to all nearby nodes, and use them to find the shortest path to more distant nodes.
The shortest path from to , d(,)=0. If all edge weights are positive, the smallest edge incident to , say (,x), defines d(,x).
We can use an array to store the length of the shortest path to each node.
Initialize each to ![]() to start.
to start.
Soon as we establish the shortest path from to a new node x, we go through each of its incident edges to see if there is a better way from to other nodes thru x.
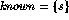
for i=1 to n,
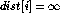
for each edge (,v), dist[v]=d(,v)
last=
while (
)
select v such that
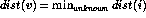
for each (v,x),
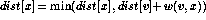
last=v
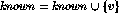
Complexity ![]()
![]() if we use adjacency lists and a
Boolean array to mark what is known.
if we use adjacency lists and a
Boolean array to mark what is known.
This is essentially the same as Prim's algorithm.
An ![]() implementation of Dijkstra's algorithm would be faster
for sparse graphs, and comes from using a heap of the vertices (ordered by
distance), and updating the distance to each vertex (if necessary)
in
implementation of Dijkstra's algorithm would be faster
for sparse graphs, and comes from using a heap of the vertices (ordered by
distance), and updating the distance to each vertex (if necessary)
in ![]() time
for each edge out from freshly known vertices.
time
for each edge out from freshly known vertices.
Even better, ![]() follows from using Fibonacci heaps,
since they permit one to do a decrease-key operation in O(1) amortized
time.
follows from using Fibonacci heaps,
since they permit one to do a decrease-key operation in O(1) amortized
time.
All-Pairs Shortest Path
Notice that finding the shortest path between a pair of vertices (,t) in worst case requires first finding the shortest path from to all other vertices in the graph.
Many applications, such as finding the center or diameter of a graph, require finding the shortest path between all pairs of vertices.
We can run Dijkstra's algorithm n times (once from each possible start
vertex) to solve all-pairs shortest
path problem in ![]() .
Can we do better?
.
Can we do better?
Improving the complexity is an open question but there is a super-slick
dynamic programming algorithm which also runs in ![]() .
.
Dynamic Programming and Shortest Paths
The four-step approach to dynamic programming is:
From the adjacency matrix, we can construct the following matrix:
, if
and
is not in E
D[i,j] = w(i,j), if
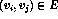
D[i,j] = 0, if i=j
This tells us the shortest path going through no intermediate nodes.
There are several ways to characterize the shortest path between two nodes
in a graph.
Note that the shortest path from i to j, ![]() , using
at most M edges consists of the shortest path from i to k
using at most M-1 edges + W(k, j) for some k.
, using
at most M edges consists of the shortest path from i to k
using at most M-1 edges + W(k, j) for some k.
This suggests that we can compute all-pair shortest path with an induction based on the number of edges in the optimal path.
Let ![]() be the length of the shortest path from i to j
using at most m edges.
be the length of the shortest path from i to j
using at most m edges.
What is ![]() ?
?
![]()
What if we know ![]() for all i,j?
for all i,j?
![]()
since w[k, k]=0
This gives us a recurrence, which we can evaluate in a bottom up fashion:
for i=1 to n
for j=1 to n
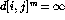
for k=1 to n
=Min(
,
)
This is an ![]() algorithm just like matrix multiplication,
but it only goes from m to m+1 edges.
algorithm just like matrix multiplication,
but it only goes from m to m+1 edges.
Since the shortest path between any two nodes must use at most n edges
(unless we have negative cost cycles), we must repeat that procedure
n times (m=1 to n) for an ![]() algorithm.
algorithm.
We can improve this to ![]() with the observation that any path
using at most 2m edges is the function of paths using at most m edges each.
This is just like computing
with the observation that any path
using at most 2m edges is the function of paths using at most m edges each.
This is just like computing ![]() .
So a logarithmic number of multiplications suffice for exponentiation.
.
So a logarithmic number of multiplications suffice for exponentiation.
Although this is slick, observe that even ![]() is slower than
running Dijkstra's algorithm starting from each vertex!
is slower than
running Dijkstra's algorithm starting from each vertex!
The Floyd-Warshall Algorithm
An alternate recurrence yields a more efficient dynamic programming formulation. Number the vertices from 1 to n.
Let ![]() be the shortest path from i to j
using only vertices from 1, 2,..., k as possible intermediate vertices.
be the shortest path from i to j
using only vertices from 1, 2,..., k as possible intermediate vertices.
What is ![]() ?
With no intermediate vertices, any path consists
of at most one edge, so
?
With no intermediate vertices, any path consists
of at most one edge, so ![]() .
.
In general, adding a new vertex k+1 helps iff a path goes through it, so
![]()
Although this looks similar to the previous recurrence, it isn't. The following algorithm implements it:
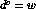
for k=1 to n
for i=1 to n
for j=1 to n
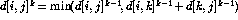
This obviously runs in ![]() time,
which asymptotically is no better than a calls to Dijkstra's algorithm.
However, the loops are so tight and it is so short and simple that it runs
better in practice by a constant factor.
time,
which asymptotically is no better than a calls to Dijkstra's algorithm.
However, the loops are so tight and it is so short and simple that it runs
better in practice by a constant factor.