Input description: An integer n.
Problem description: Generate (1) all or (2) a random or (3) the next permutation of length n.
Discussion: A permutation describes an arrangement, or ordering, of things. Many algorithmic problems in this catalog seek the best way to order a set of objects, including traveling salesman (the least-cost order to visit n cities), bandwidth (order the vertices of a graph on a line so as to minimize the length of the longest edge), and graph isomorphism (order the vertices of one graph so that it is identical to another). Any algorithm for solving such problems exactly must construct a series of permutations along the way.
There are n! permutations of n items, which grows so quickly that you can't expect to generate all permutations for n > 11, since 11! = 39,916,800. Numbers like these should cool the ardor of anyone interested in exhaustive search and help explain the importance of generating random permutations.
Fundamental to any permutation-generation algorithm is a notion of
order, the sequence in which the permutations are constructed,
from first to last.
The most natural generation order is lexicographic,
the order they would appear if they were sorted numerically.
Lexicographic order for n=3 is ![]() ,
, ![]() ,
,
![]() ,
, ![]() ,
, ![]() , and finally
, and finally ![]() .
Although lexicographic order is aesthetically pleasing,
there is often no particular reason to use it.
For example, if you are searching through a collection of files,
it does not matter whether the filenames are encountered in sorted order,
so long as you search through all of them.
Indeed, nonlexicographic orders lead to faster and simpler permutation
generation algorithms.
.
Although lexicographic order is aesthetically pleasing,
there is often no particular reason to use it.
For example, if you are searching through a collection of files,
it does not matter whether the filenames are encountered in sorted order,
so long as you search through all of them.
Indeed, nonlexicographic orders lead to faster and simpler permutation
generation algorithms.
There are two different paradigms for constructing permutations:
ranking/unranking and incremental change methods.
Although the latter are more efficient, ranking and unranking can
be applied to solve a much wider class of problems, including the
other combinatorial generation problems in this book.
The key is to define functions rank and unrank on
all permutations p and integers n, m, where |p| = n
and ![]() .
.
![]()
What the actual rank and unrank functions are does not matter as much as the fact that they must be inverses. In other words, p = Unrank(Rank(p), n) for all permutations p. Once you define ranking and unranking functions for permutations, you can solve a host of related problems:
The rank/unrank method is best suited for small values of n, since n! quickly
exceeds the capacity of machine integers, unless arbitrary-precision arithmetic
is available (see Section ![]() ).
The incremental change methods work by defining the next and previous
operations to transform one permutation into another, typically by swapping two
elements.
The tricky part is to schedule the swaps so that permutations do not repeat
until all of them have been generated.
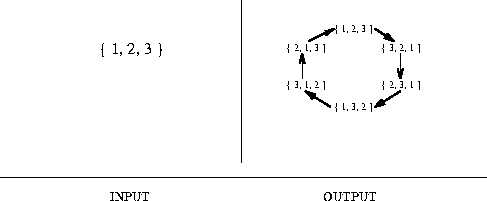
See the output picture above for an ordering of the six permutations of
).
The incremental change methods work by defining the next and previous
operations to transform one permutation into another, typically by swapping two
elements.
The tricky part is to schedule the swaps so that permutations do not repeat
until all of them have been generated.
See the output picture above for an ordering of the six permutations of ![]() with a single swap between successive permutations.
with a single swap between successive permutations.
Incremental change algorithms for sequencing permutations are tricky, but they are concise enough that they can be expressed in a dozen lines of code. See the implementation section for pointers to code. Because the incremental change is a single swap, these algorithms can be extremely fast - on average, constant time - which is independent of the size of the permutation! The secret is to represent the permutation using an n-element array to facilitate the swap. In certain applications, only the change between permutations is important. For example, in a brute-force program to search for the optimal tour, the cost of the tour associated with the new permutation will be that of the previous permutation, with the addition and deletion of four edges.
Throughout this discussion, we have assumed that the items
we are permuting are all distinguishable.
However, if there are duplicates (meaning our set is a multiset),
you can save considerable time and effort by avoiding identical
permutations.
For example, there are only ten permutations of ![]() ,
instead of 120.
To avoid duplicates use backtracking and generate the permutations in lexicographic
order.
,
instead of 120.
To avoid duplicates use backtracking and generate the permutations in lexicographic
order.
Generating random permutations is an important little problem that people stumble across often, and often botch up. The right way is the following two-line, linear-time algorithm. We assume that Random[i,n] generates a random integer between i and n, inclusive.
for i=1 to n do a[i] = i;
for i=1 to n-1 do swap[ a[i], a[ Random[i,n] ];
That this algorithm generates all permutations uniformly at random is not obvious. If you think so, explain convincingly why the following algorithm does not generate permutations uniformly:
for i=1 to n do a[i] = i;
for i=1 to n-1 do swap[ a[i], a[ Random[1,n] ];
Such subtleties demonstrate why you must be very careful with random generation algorithms. Indeed, we recommend that you try some reasonably extensive experiments with any random generator before really believing it. For example, generate 10,000 random permutations of length 4 and see whether all 24 of them occur approximately the same number of times. If you understand how to measure statistical significance, you are in even better shape.
Implementations: The best source on generating combinatorial objects is
Nijenhuis and Wilf [NW78], who provide efficient Fortran
implementations of algorithms to construct random permutations
and to sequence permutations in minimum-change order.
Also included are routines to extract the cycle structure of a permutation.
See Section ![]() for details.
for details.
An exciting WWW site developed by Frank Ruskey of the University of
Victoria contains a wealth of material on generating combinatorial objects
of different types, including permutations, subsets, partitions, and certain
graphs.
Specifically, there is an interactive interface that lets you specify
which type of objects you would like to construct and quickly returns
the objects to you.
It is well worth checking this out at
http://sue.csc.uvic.ca/ ![]() cos/.
cos/.
Combinatorica [Ski90] provides Mathematica implementations
of algorithms that construct random permutations and sequence permutations in
minimum change and lexicographic orders.
It also provides a backracking routine to construct all distinct permutations
of a multiset, and it supports various permutation group operations.
See Section ![]() .
.
The Stanford GraphBase (see Section ![]() )
contains routines to generate all permutations of a multiset.
)
contains routines to generate all permutations of a multiset.
Notes: The primary reference on permutation generation is the survey paper by Sedgewick [Sed77]. Good expositions include [NW78, RND77, Rus97].
The fast permutation generation methods make only a single swap between successive permutations. The Johnson-Trotter algorithm [Joh63, Tro62] satisfies an even stronger condition, namely that the two elements being swapped are always adjacent.
In the days before ready access to computers, books with tables of random permutations [MO63] were used instead of algorithms. The swap-based random permutation algorithm presented above was first described in [MO63].
Related Problems: Random number generation (see page ![]() ),
generating subsets (see page
),
generating subsets (see page ![]() ),
generating partitions (see page
),
generating partitions (see page ![]() ).
).