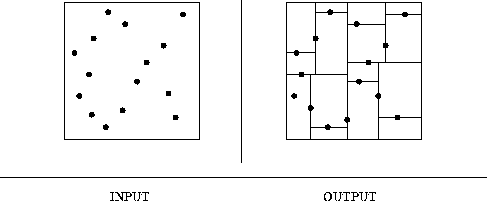
Input description: A set S of n points in k dimensions.
Problem description: Construct a tree that partitions the space by half-planes such that each point is contained in its own box-shaped region.
Discussion: Although many different flavors of kd-trees have been devised, their purpose is always to hierarchically decompose space into a relatively small number of cells such that no cell contains too many input objects. This provides a fast way to access any input object by position. We traverse down the hierarchy until we find the cell containing the object and then scan through the few objects in the cell to identify the right one.
Typical algorithms construct kd-trees by partitioning point sets.
Each node in the tree is defined by a plane
through one of the dimensions that partitions the set of points into
left/right (or up/down)
sets, each with half the points of the parent node.
These children are again partitioned into
equal halves, using planes through a different dimension.
Partitioning stops after ![]() levels, with each point in its own
leaf cell.
Alternate kd-tree construction
algorithms insert points incrementally and divide the appropriate
cell, although such trees can become seriously unbalanced.
levels, with each point in its own
leaf cell.
Alternate kd-tree construction
algorithms insert points incrementally and divide the appropriate
cell, although such trees can become seriously unbalanced.
The cutting planes along any path from the root to another node defines a unique box-shaped region of space, and each subsequent plane cuts this box into two boxes. Each box-shaped region is defined by 2k planes, where k is the number of dimensions. Indeed, the `kd' in kd-tree is short for k-dimensional tree. In any search performed using a kd-tree, we maintain the current region defined by the intersection of these half-spaces as we move down the tree.
Different flavors of kd-trees differ in exactly how the splitting plane is selected. Options include:
Nonorthogonal (i.e. not axis-parallel) cutting planes have also been used, although they make maintaining the cell boundaries more complicated.
Ideally, our partitions evenly split both the space (ensuring nice, fat, regular regions) and the set of points (ensuring a log height tree) evenly, but this can be impossible for a given point set. The advantages of fat cells become clear in many applications of kd-trees:
Kd-trees are most effective data structures for small and moderate numbers of dimensions, say from 2 up to maybe 20 dimensions. As the dimensionality increases, they lose effectiveness, primarily because the ratio of the volume of a unit sphere in k-dimensions shrinks exponentially compared to a unit cube in k-dimensions. Thus exponentially many cells will have to be searched within a given radius of a query point, say for nearest-neighbor search. Also, the number of neighbors for any cell grows to 2k and eventually become unmanageable.
The bottom line is that you should try to avoid working in high-dimensional spaces, perhaps by discarding the least important dimensions.
Implementations: Ranger is a tool for visualizing and experimenting with
nearest neighbor and orthogonal range queries in high-dimensional data sets,
using multidimensional search trees.
Four different search data structures are supported by Ranger:
naive kd-trees, median kd-trees, nonorthogonal kd-trees,
and the vantage point tree.
For each of these, Ranger supports queries in up to 25 dimensions
under any Minkowski metric.
It includes generators for a variety of point distributions
in arbitrary dimensions.
Finally, Ranger provides a number of features to aid in
visualizing multidimensional data, best illustrated by the
accompanying video [MS93].
To identify the most appropriate projection at a glance,
Ranger provides a ![]() matrix of all two-dimensional
projections of the data set.
Ranger is written in C,
runs on Silicon Graphics and HP workstations, and is
available from the algorithm repository.
matrix of all two-dimensional
projections of the data set.
Ranger is written in C,
runs on Silicon Graphics and HP workstations, and is
available from the algorithm repository.
The 1996 DIMACS implementation challenge focuses on data structures for higher-dimensional data sets. The world's best kd-tree implementations were likely to be identified in the course of the challenge, and they are accessible from http://dimacs.rutgers.edu/.
Bare bones implementations in C of kd-tree and quadtree data structures
appear in [GBY91].
See Section ![]() for details on how to ftp them.
for details on how to ftp them.
Notes: The best reference on kd-trees and other spatial data structures are two volumes by Samet [Sam90a, Sam90b], in which all major variants are developed in substantial detail.
Bentley [Ben75] is generally credited with developing kd-trees, although they have the typically murky history associated with most folk data structures. The most reliable history is likely from Samet [Sam90b].
An exposition on kd-trees for orthogonal range queries in two dimensions appears in [PS85]. Expositions of grid files and other spatial data structures include [NH93].
Algorithms that quickly produce a point provably close
to the query point are
a recent development in higher-dimensional nearest neighbor search.
A sparse weighted-graph structure is built from the data set, and the
nearest neighbor is found by starting at a random point and walking greedily
in the graph towards the query point.
The closest point found during several random trials is declared the
winner.
Similar data structures hold promise for other problems in high-dimensional
spaces.
See [AM93, AMN ![]() 94].
94].
Related Problems: Nearest-neighbor search (see page ![]() ),
point location (see page
),
point location (see page ![]() ),
range search (see page
),
range search (see page ![]() ).
).